Fauna Case Study
Author: Aggi Cieplak Figure 1: Fauna DB Backdrop
Figure 1: Fauna DB Backdrop
FAUNA:
Is it truly the perfect mixture of the most common database paradigms, all in one sophisticated model?
Table of Contents
Introduction
Fauna is the most versitile, multi-model database system to date. It determines how to best use the most common database paradigms, through tailored queries satisfying most user needs. Delivered as a global API endpoint, Fauna is a distributed serverless, document-relational database, that with it’s flexibility, meets the requirements of simple, and at the same time, demanding modern applications. The pay-as-you-go model let’s developers pay for the usage, not idle time. Let’s learn where it started, what distinguishes it from other database providers and how it compares, to see whether Fauna truly is the perfect database system to serve most modern applications today.
Brief History
-
2012:It all started with Thomson, Diamond, Weng et al. publishing the paper; ‘Calvin: Fast Distributed Transactions for Partitioned Database Systems’, a transactional protocol optimized for geographic replication, being a great inspiration for Fauna’s creation. -
2016:Fauna is created by two ex-Twitter (ex-X) engineers. It’s known to be the only database that has based its system on the Calvin Protocol.
Main Features
 Figure 2: Fauna features
Figure 2: Fauna features
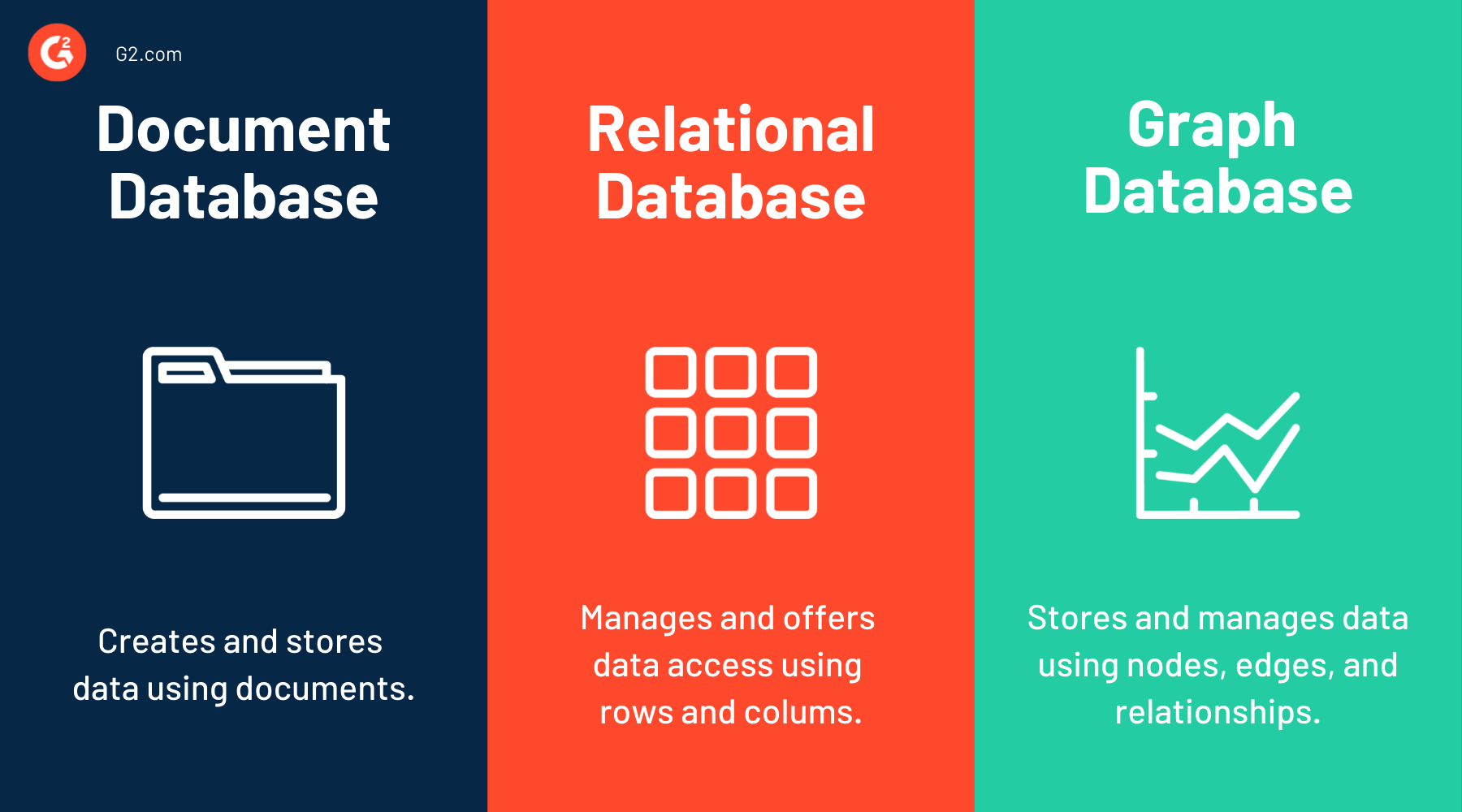
The most unique feature that Fauna has to offer is its flexibility, thanks to the way that this system handles queries and chooses the most appropriate database paradigm to satisfy the query. At the core, it’s a document-relational model, where the documents are rows and collections are equivalent to tables. Thanks to this structure, developers can execute joins across document collections, making data handling easier.
Handling data becomes even easier using the FQL native Fauna query language. It’s essentially a mix of TypeScript and SQL, allowing for complex data queries and operations, aggregations, server-side functions and more.
Another advantage of Fauna is its flexible indexing system. Developers can create secondary indexes on any nested JSON field, enabling multi-term searches, embedded data retrieval, and high-performance queries. Unlike conventional NoSQL systems, Fauna’s indexing mechanism enhances both consistency and query speed, making it easier to scale applications without sacrificing performance.
Fauna resticts access based on user identity as well as using a hierarchical database structure by default, solving for potential security risks.
A distinct architectural feature Fauna has to offer, is that it’s inspired by the Calvin Transaction Protocol, rendering it a serverless database system. The biggest aid of the Calvin protocol is how it removes the need for per-transaction locks. All coordinator nodes are stateless and scale horizontally. Its serverles nature essentially means developers don’t have to worry about infrastructure management.
Key Takeaways:
| Features | Summary |
|---|---|
| Data Modeling | Supports document-relational data with JSON stored in collections. Enables optional relationships and joins, allowing rapid model changes, schema enforcement without complex migrations, and scalability through flexible normalization. |
| Fauna Query Language (FQL) | Typescript/SQL-based query language that enables complex queries, aggregations, and data interactions. Supports serverless API functions via HTTP API and Client Drivers (JS, Python, Go, C#, Java, etc.). |
| Secondary Indexes | Can be created for any nested JSON field. Indexes support multiple terms, values, and embedded data, improving query performance and consistency. |
| Security and Access Control | Implements identity-based access control with a hierarchical database structure to mitigate security risks. |
| Calvin Transaction Protocol | Ensures global consistency with no per-transaction locks, horizontal scaling, and stateless nodes. |
| Serverless and Scalable | Requires no user infrastructure management, supports global replication, offers fault tolerance, and automatically scales based on demand. |
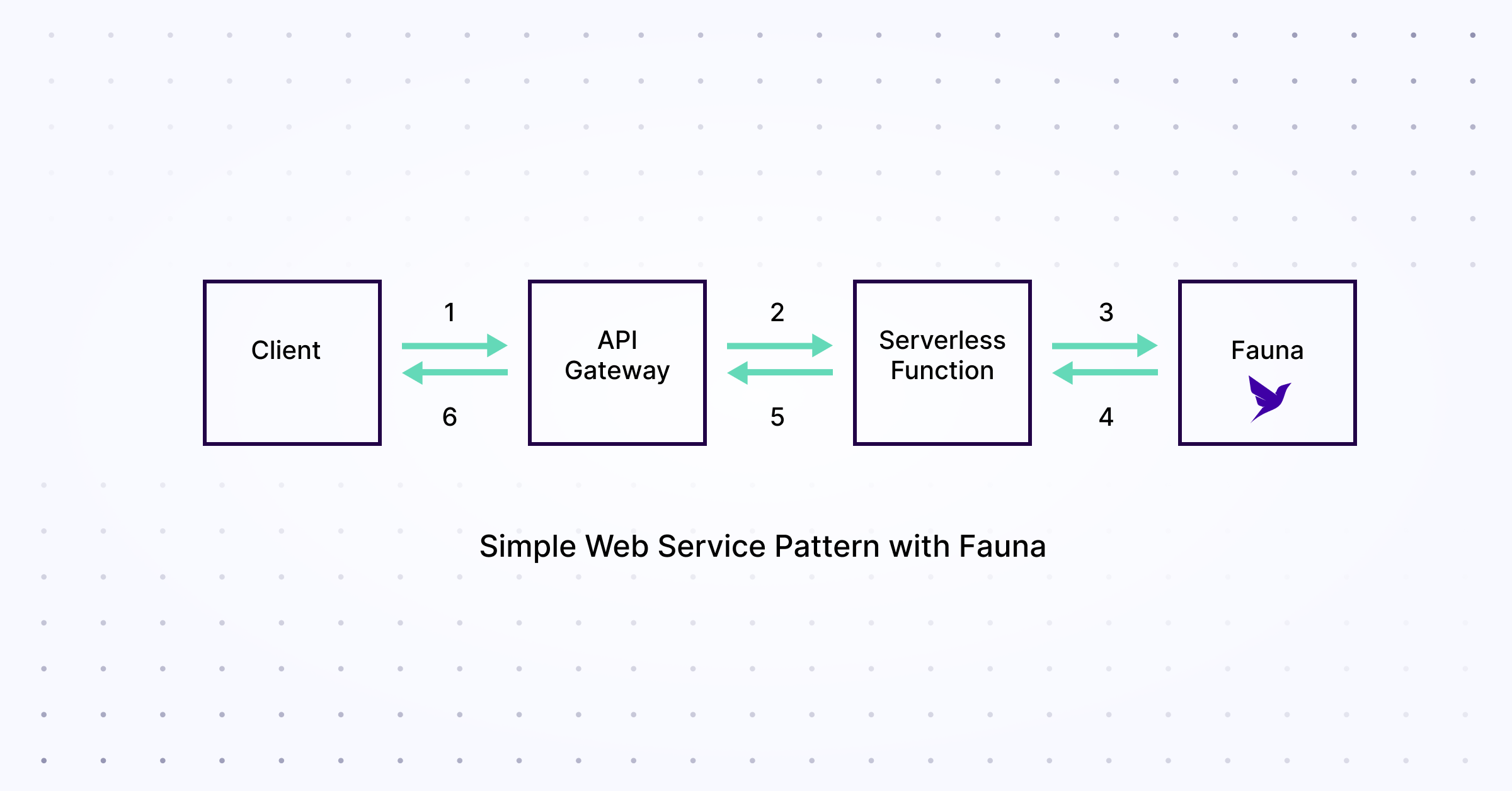 Figure 3: Fauna web service pattern
Figure 3: Fauna web service pattern
{kind=link}
To help create a more fully fledged picture of Fauna, below is a table showcasing its strengths and weaknesses.
Strengths and Weaknesses:
| Strengths | Weaknesses |
|---|---|
| Consistency per transaction – Ensures data remains consistent, preventing corruption or conflicts. | Read-only transactions execute at snapshot isolation – Can yield stale data in rapidly changing environments (e.g., real-time analytics). |
| FQL allows highly complex queries – More powerful than many NoSQL query languages, supporting joins, relations, indexes, and event streams. | Learning curve for FQL – Developers familiar with SQL or MongoDB Query Language may need time to adapt. |
| Serverless infrastructure – Developers don’t need to manage servers, scaling, or infrastructure, reducing operational complexity. | Limited customization options – Since Fauna is fully managed, users cannot modify storage engines, query execution, or replication strategies. |
| Automatic scaling with global replication – Fauna distributes data globally and replicates automatically without requiring manual sharding. | Potentially expensive at scale – While Fauna is cost-effective for small projects, pricing can increase significantly with high-volume workloads. |
Market Comparison
As every project has its unique needs, it’s vital to consider what other database providers have to offer compared to Fauna, before judging it’s powers. MongoDB and PostgreSQL are some of the most compelling database resources used in the developer market today.
MongoDB
 Figure 4: Fauna v.s. MongoDB
Figure 4: Fauna v.s. MongoDB
MongoDB is a document database. It supports Query API and CRUD, supports multiple storage engines and allows for horizontal scaling, through sharding. Here is how these central areas of Fauna compare with MongoDB.
| Feature | Fauna | MongoDB |
|---|---|---|
| Data Model | Flexible (NoSQL document model) | Flexible schema (NoSQL document model) |
| Multi-Tenancy | Native | Native |
| Hosting | Serverless | Self-managed, supports serverless (MongoDB Atlas) |
| Maintenance | Fully managed (abstracted) | Self-managed (requires setup and monitoring) |
| Middleware | Supports transactions, joins, relations, indexes, views, event streams in JSON | Natively supports functions, triggers, aggregation pipelines |
| Query Predictability | Predictable queries with explicit indexing | Query optimization varies across versions |
| Security | Dynamic security model | Authentication, RBAC (Role-Based Access Control), TLS/SSL encryption |
| Connection Management | Modern stateless HTTPS | Uses drivers, connection pooling, and authentication-based connections |
| Replication | Automatic with global distribution and Calvin protocol | High availability replica sets for distributed environments |
| Data Consistency | Distributed consistency (ACID-compliant) | ACID transactions supported for multi-document operations (optional) |
| Cost | Can get expensive at scale | More cost-effective for large-scale projects (self-hosting available) |
Key Takeaways:
-
Fauna is fully serverless and globally distributed with strong consistency, making it great for modern web applications.
-
MongoDB offers greater control, flexibility, and self-hosting options, making it better for large-scale, complex NoSQL applications.
PostgreSQL
 Figure 5: Fauna v.s. PostgreSQL
Figure 5: Fauna v.s. PostgreSQL
Another well known database distributor is PostgreSQL. It is a fully open-source, object-relational database system. How does it compare to Fauna in the same key areas?
| Feature | Fauna | PostgreSQL |
|---|---|---|
| Data Model | Flexible (NoSQL document model) | Relational (SQL-based) but supports JSONB (semi-structured data) |
| Multi-Tenancy | Native | Manual orchestration required (can be configured) |
| Hosting | Serverless | Self-managed or cloud-managed (AWS RDS, Google Cloud, etc.) |
| Maintenance | Fully managed (abstracted) | Requires self-maintenance, patching, and tuning |
| Middleware | Supports transactions, joins, relations, indexes, views, event streams in JSON | ORM-dependent to simplify object-relational mapping |
| Query Predictability | Predictable queries with explicit indexing | Query optimization varies across versions |
| Security | Dynamic security model | Advanced security features, fine-grained access control |
| Connection Management | Modern stateless HTTPS | Uses PgBouncer for connection pooling in high-traffic environments |
| Replication | Automatic with global distribution and Calvin protocol | Manual setup required (supports streaming replication, logical replication) |
| Data Consistency | Distributed consistency (ACID-compliant) | ACID-compliant, multi-region support possible (via tools like Patroni, Citus) |
| Cost | Can get expensive at scale | Free open-source, but managed services (AWS RDS, etc.) increase cost |
Key Takeaways:
-
Fauna offers a modern, NoSQL, globally distributed approach with built-in ACID compliance.
-
PostgreSQL is a powerful, structured relational database with deep SQL support, advanced security, and strong ecosystem tools.
Getting Started
If you have already decided that Fauna is indeed the best tool for you project’s needs, go ahead and start your journey. Here is a quick and well documented guide for how to get started with Fauna.
Figure 6: Fauna DB Backdrop
Conclusion
Is Fauna DB spice and everything nice?
To put it simply: No, because there is no perfect database. Is it the best, well-documented tool, consisting of the best parts of database paradigms, out on the market today? I would say: Sure. As for the longer answer; it truly depends on your specific application needs. Fauna is great for modern, global and smaller to mid-scale applications (if cost-effectivity is a concern), that is serverless and therefore also requires less user driven maintenance. This database however, gives you little customization possibilities and the learning curve for FQL might add to the time spent on your application overall. Nevertheless, this case study is by no means exhaustive of the topic, and it’s most recommended to use it as an introductory piece in your journey of making a decision: for Your application, Yourself and Your Team.